
統計学とは、簡単に言うと標本の情報から母集団の状況を推測する学問です。母集団とは本来調査するべき全員を指し、その一部を標本ということができます。

無作為抽出の仮定と母平均
無作為抽出の仮定を用いると、階級値×相対度数の合計=平均値をあてはめることができ、ここから出した平均値を母平均といいます。
Sponsored Link
前回の95%信頼区間とはでは95%信頼区間をみました。今回は母平均についてみていきたいと思います。

無限にある母集団から出てきた一部のデータから母集団を推定することをやってきておりますが、今回は以下の例をまず見てください。
ドラえも〇の四次元ポケットがあったとする。四次元ポケットの中に、「1」、「3」、「5」と書かれたくじが無限に入っているが、1が出る確率は50%、3が出る確率は30%、5が出る確率は20%であるという。この四次元ポケットから、くじを引く作業を行う。
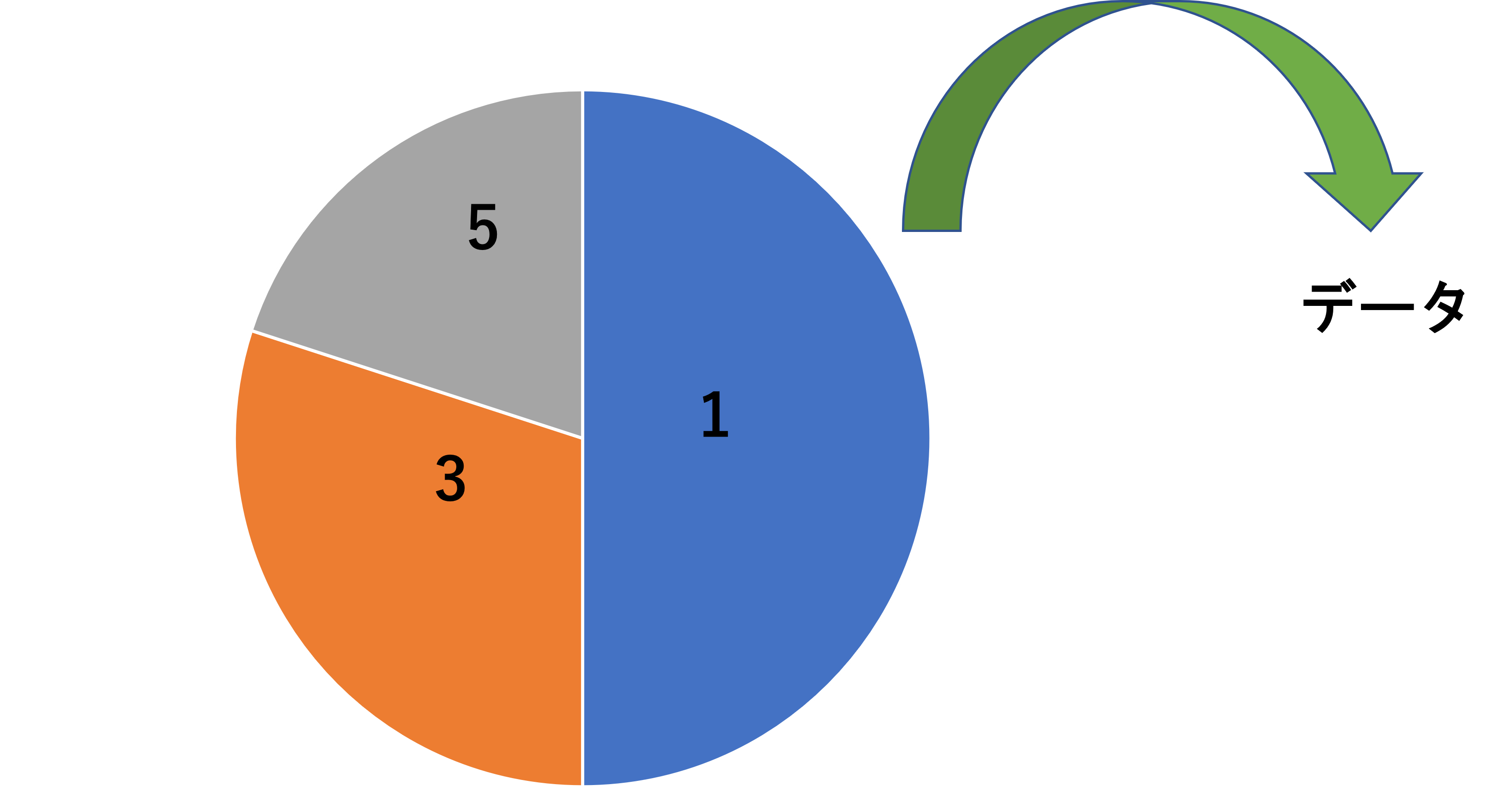
この例において、十分な回数くじ引きを繰り返していくとデータの相対度数は母集団(四次元ポケット)のものとほぼ同じになり、データから作ったヒストグラムと母集団のヒストグラムはほぼ一致することになります。おそらくこれは私が説明するまでもなく直感的にわかるかと思います。このような仮定を無作為抽出の仮定と言います。
Sponsored Link
Sponsored Link
では、先ほどの四次元ポケットから10回くじ引きをしたとしましょう。そうすると、1が5回、3が3回、5が2回出ました。この時の平均値を出してみると、
(1×5+3×3+5×2)÷10=2.4
となります。ここで少し手間ですが、先ほどの式は以下のようにも変形できます。
1×5÷10+3×3÷10+5×2÷10=2.4
なぜこんな面倒な式変形をしたかというと、(階級値×度数÷全データ数)の和=平均値という形にしたかったからです。さらに度数÷全データ数=相対度数であることから、
階級値×相対度数の合計=平均値
ということができます。
では、ここで先ほどの無作為抽出の仮定を利用すると、データから作ったヒストグラムと母集団のヒストグラムはほぼ一致するので階級値×相対度数の合計=平均値もあてはめることができます。相対度数は四次元ポケットからその数字が出てきやすさと置き換えることができるので、
1×0.5+3×0.3+5×0.2=2.4
となります。数字としてはデータと同じですが、階級値×相対度数の合計=平均値ということを意識してください。このような母集団の平均値を母平均と言います。
平均値はデータが広がって存在している中から1点全データを代表する数値として選び出したもので、そのためデータたちは平均値の近くに分布しているという話をしましたが、母平均においても同じ事が言えます。
就職や転職でお悩みの方はコチラ!私はここで年収120万円上がりました
Sponsored Link