
多糖類のままではエネルギー源として利用されず、消化、吸収され単糖類になる必要があります。糖質の代謝には解糖系やクエン酸回路などがあり、エネルギー源を生み出します。グリコーゲンは貯金として貯められ、空腹時にグルコースに戻され血糖になります。

疫学データの指標、誤差、精度、正確度
疫学データの観察値の真の値からのずれを誤差と呼び、偶然誤差と系統誤差があります。偶然誤差の大きさは精度と呼ばれ、系統誤差の大きさは正確度と呼ばれます。
Sponsored Link
前回のコホート研究と症例対照研究、相対危険度、寄与危険度、オッズ比の計算ではコホート研究と症例対照研究についてみました。今回はこれらの疫学の研究から得られたデータに関する指標を見ていきたいと思います。今回のテーマは薬学生が大嫌いな統計に関わるジャンルでもあります(笑)まず疫学の考え方を例とともに再度確認します。
例えば、日本人がラーメンが好きかどうかを調べようとしました。この時本当であれば、日本人全員に一人ずつ聞き取りをすることが必要です。しかし、現実的には全員に聞き取ることは難しいため、一部の代表者に聞き取りをして調査することになります。この例における、日本人全員を母集団と呼び、その値は真の値と呼びます。そして一部の代表者を標本と呼び、その値は観察値と呼びます。

ちなみに私はラーメンが好きで、ラーメン嫌いな人って見たことが無い気がします・・・みんなラーメン大好きですよね!!(笑)それはさておき、これを抑えた上で次の誤差を見てみましょう。
Sponsored Link
Sponsored Link
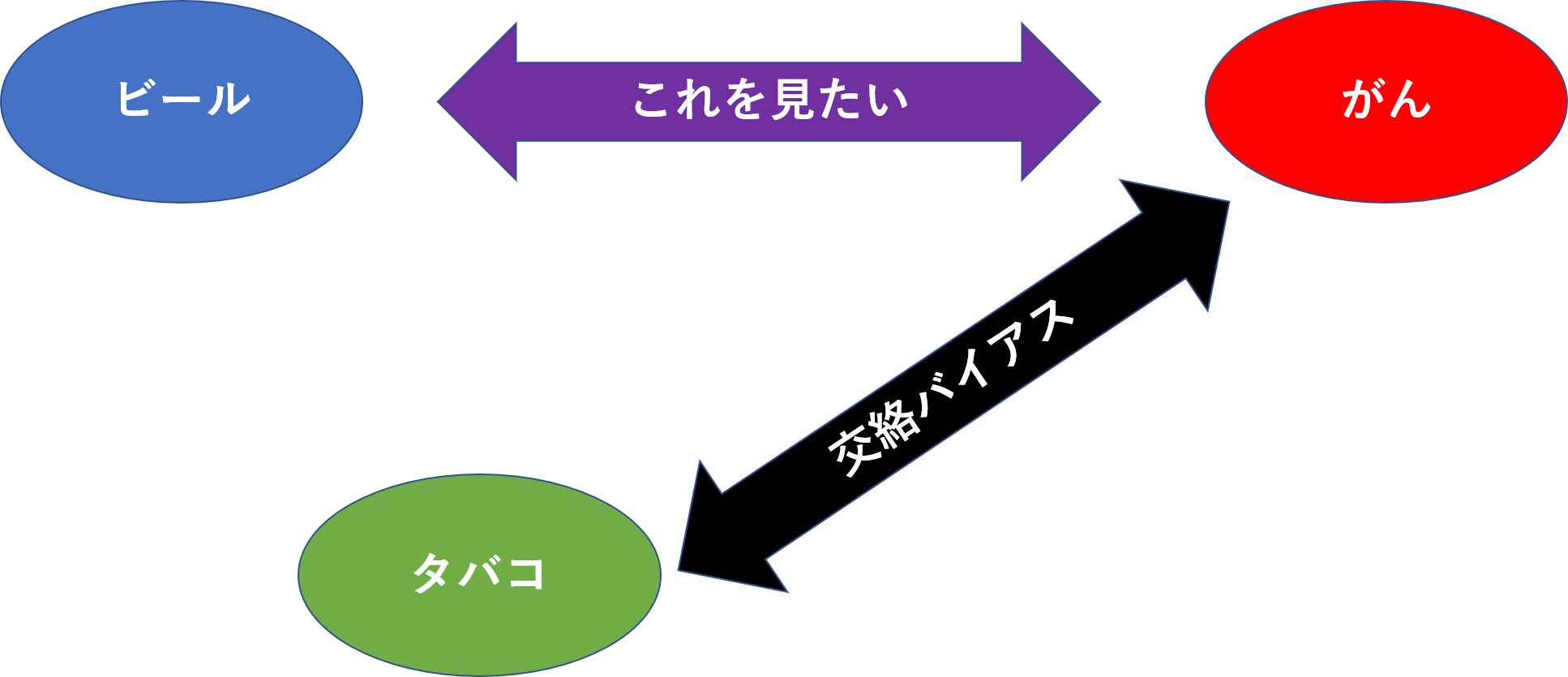
疫学のデータは観察値であるため、真の値から誤差が出てきます。方向性のない誤差のことを偶然誤差と呼びます。偶然誤差は標本誤差とも呼ばれ、防ぎようのない誤差のことです。それに対して、方向性のある誤差のことを系統誤差と呼びます。つまりは誤差となる原因があり、系統誤差には以下のようなものがあります。
例えばビールとがんの関係をみたいとするなら、
となります。
偶然誤差の大きさは精度と呼ばれます。精度が低くなると信頼性が悪くなります。それに対して系統誤差の大きさは正確度と呼ばれ、正確度が低くなると偏りが大きくなります。
例えば、以下のような観察値が得られたとするならば、
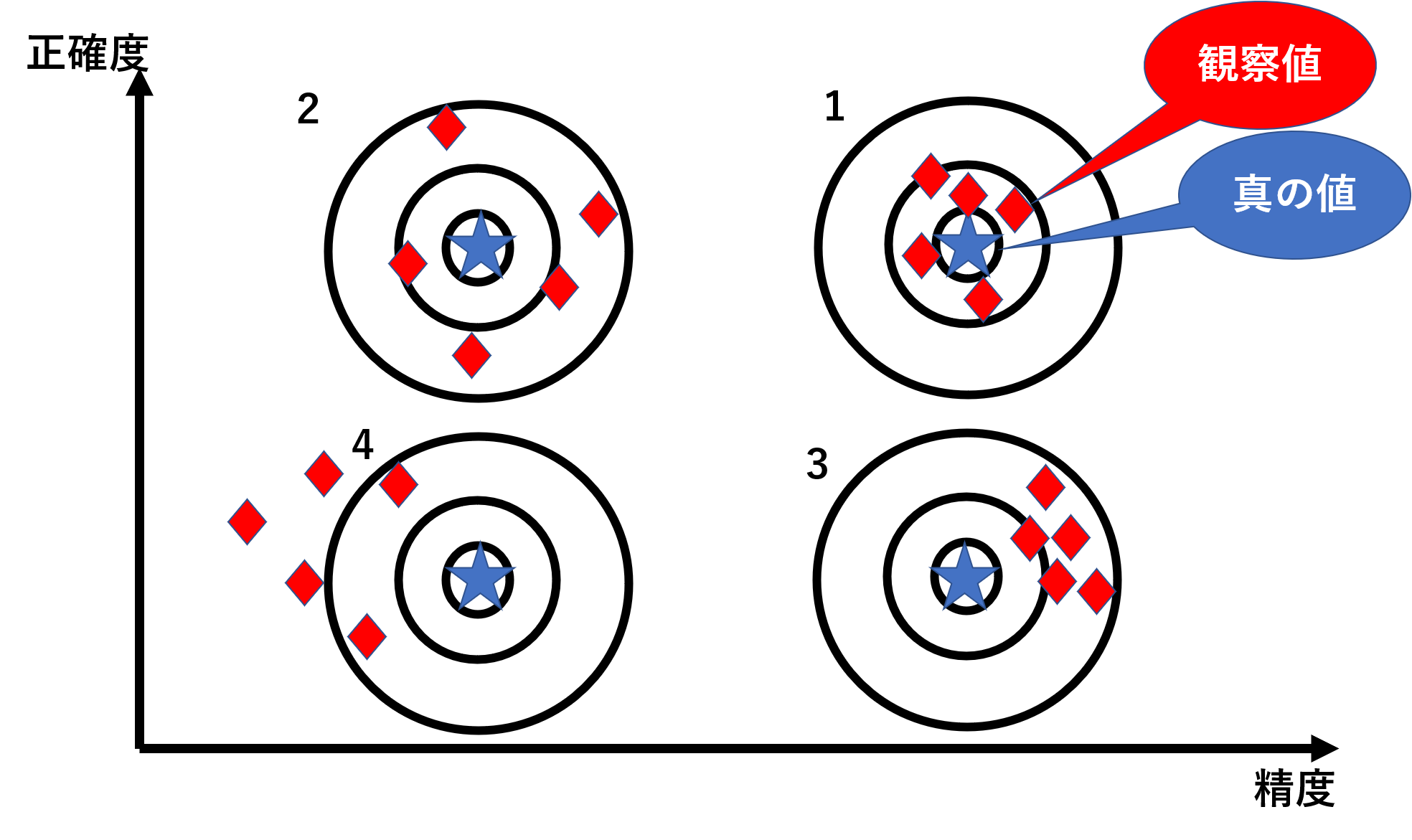
と言えます。この精度と正確度の違いをしっかりと抑えておきましょう。
就職や転職でお悩みの方はコチラ!私はここで年収120万円上がりました
Sponsored Link